Article 3.2 - Practical Usages of Quantum Computing - Part 2

This article will require some basic understanding in the area of QM and QC and there is sufficient content shared in previous articles to prep the readers for the topics I am going to discuss in this one.

Article 1 - https://www.qcguy.com/blog-1-quantum-mechanics-the-basis-of-quantum-computing/
Article 2 - https://www.qcguy.com/blog-2-quantum-computing-revolutionary-and-not-just-evolutionary/
Article 3 - https://www.qcguy.com/blog-3-quantum-computing-the-inner-workings/
Article 4 - https://www.qcguy.com/blog-3-1-practical-usages-of-quantum-computing-part-1/
After a long hiatus as a writer on QCGUY.com, thanks to the push from my friend and a guest author on this website, Stuart Dee, I have returned to continue on my previous article that I authored 5 years ago, in 2021 – Practical usages of Quantum Computing - Part 1.
At the time, I wrote about randomness, nitrogenase and cryptography. If I continue that discussion honestly, the first thing to say is this: as of May 2026, quantum computing has not yet reached broad, end-to-end deployment with conclusive classical-beating advantage on a problem of real-world economic consequence. Even Google’s own recent applications framework places true deployment at the far end of the journey and argues that the present bottleneck is still the link between hard quantum problem instances and useful real workflows. [1]
However, it would be equally wrong to conclude that nothing practical is happening. The strongest evidence now comes from hybrid workflows in which a quantum computer acts as a specialized subroutine inside a larger classical or HPC stack. In chemistry, researchers from Cleveland Clinic[2], RIKEN[3], and reported a heterogeneous quantum-classical protein-ligand study at 12,635 atoms using up to 94 qubits on two 156-qubit processors; in optimization, selected MaxCut and materials-design studies have moved beyond toy instances into experimentally validated or strongly benchmarked territory; and in finance, and reported a bond-trading pilot with measurable out-of-sample gains. None of that is a universal breakthrough, but it is practical research in the strict sense of the phrase: it touches real datasets, real workloads, and real system-level constraints. [4]
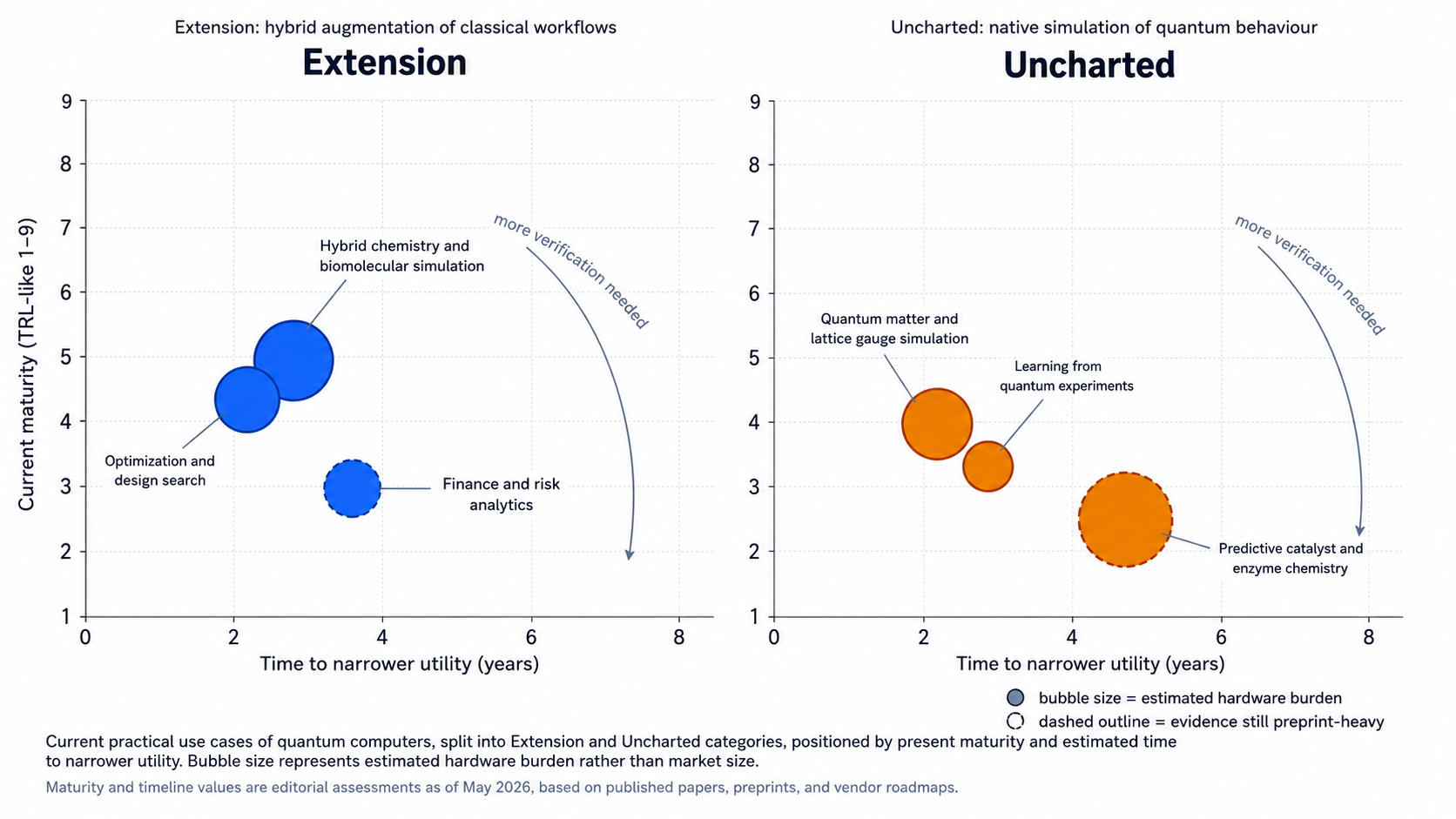
Using the definitions from Part 1 exactly as written, most credible 2026 use cases still fall under Extension. They do not replace the classical stack; they stretch it. The more profound scientific promise remains in Uncharted, where the target system is itself quantum and where the aim is not just speed, but faithful simulation of nature. That is also where the evidence becomes scientifically exciting and commercially uncertain at the same time. [5]
From the Previous Article to This One
In Part 1, I defined the two categories as follows:
Extension — “QC usages that are classified as extension mean that those particular use-cases aren’t possible today in classical computers due to the lack of speed they offer and hence QC acts as an extension of the capabilities provided by today’s classical computers due to the interference and parallelism properties of qubits that can be exploited using a QC.”
Uncharted — “QC usages that are classified as uncharted are the ones where they are beyond the capability of classical computers and can only be solved/run using a QC. These are the type of use-cases where it is required to mimic nature’s behaviour to arrive at a solution.”
That distinction still works, and in fact it works better today than many of the louder marketing phrases around “advantage” or “supremacy.” The safest way to read the present moment is this: Extension is where the current evidence is strongest, because hybridization lets researchers extract targeted value from imperfect hardware; Uncharted is where the long-range scientific case is strongest, because many-body quantum systems, gauge theories, and chemically hard active spaces are exactly the sort of things quantum machines ought to be good at, once the hardware catches up. [6]
Extension
Hybrid quantum chemistry and biomolecular simulation
What it is. Here the quantum computer is used to solve or sample especially difficult fragments of an electronic-structure problem, while the surrounding workflow—embedding, orbital selection, tensor or subspace reduction, and large-scale linear algebra—remains classical. That approach has now progressed from very small molecules to biologically meaningful systems. A 2025 CS-VQE study computed the dissociation curve of molecular nitrogen on superconducting hardware, and a 2026 heterogeneous workflow used two 156-qubit Heron-class processors, up to 94 active qubits, and two supercomputers to study protein-ligand complexes with 11,608 and 12,635 atoms. Separately, and showed a hybrid chemistry workflow using reliable logical qubits, HPC, and AI to estimate a catalytic active-space ground-state energy. [8]
Current evidence and status. The nitrogen study is notable because it did not merely reproduce the easiest chemistry benchmark; it treated bond breaking, where static correlation matters, and did so with a 5-qubit contextual subspace against active-space references that would otherwise require 8 to 14 qubits in the chosen setup. The 2026 protein-ligand preprint is notable for scale as much as for chemistry: 9,200 circuits, over 100 hours of QPU time, up to 94 qubits used, and fragment energies reported at coupled-cluster-quality accuracy within the embedding workflow. The logical-qubit chemistry case from and is narrower, but important for a different reason: it showed that logical qubits could outperform the underlying physical qubits in an end-to-end chemistry-related subroutine. [9]
Key limitations. None of these results yet proves end-to-end quantum advantage for practical chemistry. The nitrogen result explicitly says the goal was not quantum advantage; the protein-ligand result is still a preprint and depends on aggressive hybrid decomposition; and the logical-qubit chemistry workflow solved a classically checkable active-space problem, not a chemically decisive instance beyond classical reach. More broadly, the fault-tolerant molecular-systems literature still emphasizes the gap between improved algorithms and full practical implementation. [10]
Near-term roadmap. The most credible next step is not “quantum drug discovery” in the grand marketing sense. It is narrower and more believable: more fragment-based biomolecular workflows, more active-space calculations on logically protected qubits, and more combinations of QPUs with classical embedding and AI models. ’s roadmap targets near-term quantum advantage by the end of 2026 and a fault-tolerant system in 2029; says its path leads to hundreds of logical qubits by the end of the decade; and argues that around 100 logical qubits could plausibly open the door to scientific quantum advantage. These are vendor roadmaps, not guarantees, but they point in the same general direction. [11]
Optimization and design search
What it is. Optimization remains attractive because many industrial problems can be mapped to MaxCut, QUBO, constrained feature selection, or related discrete search forms. In practice, though, the useful formulations today are not generic “quantum solves optimization” claims. They are much more specific: compressed encodings, hybrid post-processing, annealing-assisted model pruning, or domain-constrained design loops. [12]
Current evidence and status. Two results stand out. First, a 2025 Nature Communications paper showed selected MaxCut instances with up to 2,000 vertices encoded into 17 trapped-ion qubits, with approximation ratios beyond the worst-case hardness threshold on raw experimental data and without measurement error mitigation. Second, a 2026 npj Computational Materials paper used quantum annealing inside a quantum-assisted machine-learning workflow to identify a high-entropy alloy that was then synthesized and experimentally validated, with reported yield strength of 568 MPa, compressive strain above 40% without fracture, and corrosion performance nearly an order of magnitude better than 304 stainless steel. A newer 2026 end-to-end benchmarking preprint further reports that a hybrid solver on Heron processors can be competitive with some multicore classical baselines at sub-second wall-clock times, though it does not dominate the strongest GPU or enhanced parallel-tempering baselines. [13]
Key limitations. This is also where hype can outrun the evidence most easily. Optimization performance is notoriously instance-dependent, classical heuristics are still improving fast, and success on selected benchmarks does not establish broad commercial superiority. Even the more careful recent benchmarking papers show a mixed picture rather than a clean quantum win. That means the right conclusion is not that optimization is solved, but that it is becoming measurable in a more disciplined way. [14]
Near-term roadmap. The credible path here is domain-specific rather than universal: materials search under hard physical constraints, combinatorial subroutines inside larger pipelines, and hybrid solvers where the QPU provides proposal states or compressed encodings while the classical side still performs presolve and cleanup. In other words, optimization is likely to become useful first where a business problem already tolerates heuristics and where the quantum part can be benchmarked end-to-end, not where someone expects a miraculous replacement for Gurobi, branch-and-bound, or the best GPU heuristics. [15]
Finance and risk analytics
What it is. Finance has two distinct quantum stories. The long-range story is algorithmic: amplitude-estimation-style methods for pricing, risk, and Monte Carlo can in principle improve convergence over classical Monte Carlo. The nearer-term story is hybrid: quantum feature transforms, data loading, and structured embeddings used alongside ordinary machine-learning or execution systems. [16]
Current evidence and status. The most concrete 2025 result is the – bond-trading study. Using real production-scale intraday trade-event data and quantum-transformed features generated on Heron processors, the authors report up to roughly 34% relative gain in out-of-sample test scores compared with models using the original data or noiseless quantum-simulator transforms. In parallel, the more formal finance literature remains strongest in risk-analysis algorithms: ’s published quantum risk-analysis work continues to show asymptotic improvements over classical Monte Carlo, and newer state-preparation work for financial distributions aims to reduce one of the most stubborn practical bottlenecks. [17]
Key limitations. The finance evidence is still thinner than the press releases might suggest. The bond-trading result is a preprint plus a corporate announcement, not yet a mature peer-reviewed production study, and the authors themselves note that current hardware noise may be contributing to the observed effect rather than merely degrading it. Meanwhile, the elegant amplitude-estimation story still runs into hard data-loading and circuit-depth constraints, which means the long-term theoretical advantage has not yet turned into a broadly deployable front-office or risk-engine product. [18]
Near-term roadmap. The likely first use of quantum in finance is therefore as an adjunct: offline feature generation, benchmark sandboxes for structured risk measures, or narrow hybrid transformations inside larger models. More ambitious credit-risk and derivative-pricing workflows remain plausible, but they look much more like early-fault-tolerant or fully fault-tolerant stories than immediate NISQ-era wins. [19]
Uncharted
If the previous section was about quantum computers extending the reach of classical workflows, this section is about the cases where the target phenomenon is itself quantum and the classical difficulty appears structural. Here the science is often more compelling than the business case, and that is not a contradiction. It simply means the best near-term value may emerge first in scientific understanding before it emerges in enterprise deployment. [20]
Predictive catalyst, enzyme, and drug-scale chemistry
What it is. This is the use case most often described as quantum computing’s “killer application,” and for good reason. Many of the central questions in catalysis, enzyme function, and strongly correlated active-space chemistry are fundamentally quantum-mechanical and become very costly for classical approximations once the relevant correlation structure grows. The ambition here is not merely to accelerate a classical workflow, but to deliver chemically predictive answers in places where classical approximations fail or become too expensive to trust. [21]
Current evidence and status. The best current evidence is still directional, not definitive. The two-logical-qubit catalyst study from and showed a chemistry-relevant active-space calculation within chemical accuracy and a better estimate than the underlying physical-qubit computation. The 2025 WIREs survey on fault-tolerant molecular algorithms argues that early fault-tolerant devices already offer a plausible bridge between theory and practice by lowering circuit-depth and ancilla costs. And the 2026 protein-ligand HQC work shows how quickly hybrid biomolecular chemistry is scaling. Still, none of these, on its own, is a decisive demonstration of practical quantum advantage in medicinal chemistry or catalysis. [22]
Key limitations. The missing pieces are clear enough. We need more logical qubits, deeper reliable circuits, better end-to-end resource accounting, and—this point matters greatly—specific problem instances where a quantum solution can be tied to an actual scientific or industrial decision. That last gap is exactly the one highlighted by ’s applications framework. [23]
Near-term roadmap. My assessment is that late-2020s progress will likely focus on active-space catalysts, benchmark enzyme motifs, and narrow drug-relevant subsystems rather than full end-to-end protein design. Broader medicinal-chemistry impact looks more like an early-2030s possibility if logical-qubit counts and error rates improve roughly in line with current roadmaps. That date range is an author assessment, not a vendor promise. [24]
Quantum matter and lattice gauge simulation
What it is. If one asks where quantum computers are most naturally suited, the answer is often “simulating other quantum systems.” That includes magnetic materials, nonequilibrium spin dynamics, Fermi-Hubbard-like models, and gauge theories relevant to high-energy physics. This sits squarely in your Uncharted category because the aim is to mimic nature’s own quantum evolution rather than merely speed up an existing classical routine. [25]
Current evidence and status. The evidence here is scientifically serious. researchers used Krylov quantum diagonalization to estimate low-lying energies of Heisenberg systems on two-dimensional lattices up to 56 sites on superconducting hardware. Another 2025 Nature Physics study used a trapped-ion mixed-dimensional platform—one qutrit and four qubits for the minimal plaquette setup—to simulate two-dimensional lattice QED, including pair-creation dynamics and gauge-field truncation control. In a different hardware model, reported beyond-classical computation in nonequilibrium quantum simulation of spin dynamics. These are not the same kind of result, but together they show that quantum simulation is moving from abstract promise to disciplined experimental science. [26]
Key limitations. Even so, caution is warranted. The workloads are narrow, verification is highly problem-specific, and some advantage claims immediately attract legitimate scrutiny about what exactly was compared to what classical baseline. That does not erase the progress; it merely means that this field must remain unusually strict about verifiability. [27]
Near-term roadmap. Expect more results of the following kind: verifiable many-body dynamics, gauge-theory primitives, and materials-relevant model simulation where correctness can be checked against symmetries, limiting cases, or small-classical-shadow regimes. What remains uncertain is how quickly those scientific successes will translate into direct industrial leverage in batteries, catalysts, or magnetic materials. [28]
Learning from quantum experiments
What it is. This use case is easy to miss because it does not look like “quantum machine learning” in the fashionable enterprise sense. It is more precise than that. The question is whether a quantum machine can learn properties of a quantum system from quantum data with fewer experiments than a classical measurement-and-postprocessing pipeline would require. [29]
Current evidence and status. On that narrower question, the evidence is strong. Huang and coauthors proved exponential advantages in several learning-from-experiments tasks and demonstrated substantial advantage using up to 40 superconducting qubits and 1,300 gates. Later, ’s 2025 “Quantum Echoes” / OTOC work framed verifiable quantum advantage as a route toward practical Hamiltonian learning in NMR and related spectroscopy-like settings. This does not mean generalized classical tabular ML will suddenly become quantum-native. It means that where the data source is already quantum, quantum learning can be fundamentally better aligned to the problem. [30]
Key limitations. The main limitation is scope. This is practical primarily for laboratory and sensing workflows where the underlying data are quantum, not for every classification or regression problem dressed up with a quantum circuit. That broader QML literature still needs harder benchmarking and stricter end-to-end accounting. [31]
Near-term roadmap. The best near-term fits are spectroscopy, device calibration, Hamiltonian learning, and quantum-sensing pipelines where the verification story is cleaner than in generic business AI. In other words, the first practical value is likely to appear in scientific instrumentation and quantum labs, not in the average corporate ML stack. [30]
Comparative View
The table below is a synthesis, not a vendor scorecard. The maturity scores and timeline estimates are my assessments on a 1–9 TRL-like scale, inferred from the cited papers, pilots, and roadmaps.
A useful way to read that table is as follows: Extension use cases are closer to hybrid workflow value but still wrestling with “is the quantum piece really doing enough?”; Uncharted use cases are further from deployment but closer to the original reason many of us cared about quantum computing in the first place.
| Use case | Category | Current maturity | Required qubit count / quality | Evidence of practical or classical-beating value | Timeline estimate |
| Hybrid chemistry and biomolecular simulation | Extension | 5/9 | Current demos: 5–94 active physical qubits; logical demo at 2 logical qubits; likely 50–200 logical qubits for narrower decision-grade active-space utility (author assessment) | Strong hybrid workflow evidence; no end-to-end broad advantage yet | 2–5 years for narrow scientific utility |
| Optimization and design search | Extension | 4/9 | Current gate-model demos: 17–23 trapped-ion qubits; annealing-based workflows depend heavily on embedding and problem structure | Competitive or better results on selected instances; alloy design experimentally validated; no universal advantage | 1–4 years for domain-specific pilots |
| Finance and risk analytics | Extension | 3/9 | Current pilots use today’s physical QPUs; core amplitude-estimation utility likely needs EFT/FT logical qubits (author assessment) | One real-data bond-trading pilot with measurable gains; strong asymptotic theory, weak deployment evidence | 2–6 years for adjunct analytics |
| Predictive catalyst, enzyme, and drug-scale chemistry | Uncharted | 2/9 | Early logical demos at 2–12 logical qubits; broader utility likely needs ~100+ logical qubits (author assessment) | Scientifically compelling; no decisive real-world advantage yet | Late 2020s to early 2030s |
| Quantum matter and lattice gauge simulation | Uncharted | 4/9 | Current demos range from mixed qubit–qutrit plaquettes to 56-site superconducting KQD and annealer-specific large systems | Narrow scientific use cases already credible; industrial translation still indirect | 1–4 years for scientific utility |
| Learning from quantum experiments | Uncharted | 3/9 | Demonstrated with up to 40 superconducting qubits and 1,300 gates; reliability and integration remain open issues | Rigorous advantage in quantum-data tasks; limited enterprise relevance so far | 2–5 years for lab and sensing workflows |
This synthesis is supported by the current chemistry, optimization, finance, quantum-simulation, and logical-qubit evidence discussed above, as well as by the application-framework and roadmap literature. [32]
Milestones and Uncertainties
A sensible reading of the current roadmaps is that the field is converging on a two-step path: first, hybrid utility on narrow scientific or industrial subroutines; second, logically protected computations that make genuinely quantum-native applications more reliable and more economically interesting. , , , and differ in architecture and timelines, but not in that broad structure.
The Mermaid timeline below is therefore best read as an author assessment informed by the cited papers and vendor roadmaps, not as a promise that the calendar will behave itself.

Open questions and limitations. Three questions still dominate the field. First, which hybrid wins remain intact after strict end-to-end accounting against the best classical baselines? Second, which chemistry instances are both classically hard and genuinely useful to scientists or engineers? Third, how quickly will logical-qubit demonstrations scale from proof-of-concept to application-relevant runtimes? These are not minor details; they are the central questions that separate real utility from beautiful lab work. [34]
Disclaimer - The reading of all information on this article is of your own free will. If you do not accept these Terms and Conditions, you should cease reading this article immediately. If you do however want to read some awesome QC related articles, please don’t leave just yet.
I reserve the right to change any of these Terms and Conditions at any given time on this article.
Even though I work very hard to provide you with up-to-date information (through thorough research and eating lots of cookies while re-writing already published articles), I make no representations or warranties of any kind (expressed or implied) about the completeness, accuracy, reliability, suitability or availability of any information, products, services or related graphics contained on the QCGuy.com for any purpose.
I aim to provide you with accurate information at the time of publishing, but some information will understandably be less accurate as time passes. Should you find any inaccurate information, please do not hesitate to contact me. I will drop everything, get behind my “classical computer” and correct this world shocking mistake right away… or as soon as I finish my cup of tea.