Part One - The Architecture You Inherit

By Deepa Shinde
Why I am writing this
A confession before we begin. I am not a quantum physicist. I have spent the last few years sitting beside people who are, asking the same question in a hundred different ways: what is actually going to be different, and when? This series is my attempt to answer that in plain English - for the people who keep asking me the same thing over coffee. The hype is exhausting. The science is genuinely thrilling. The job, as I see it, is to separate the two without losing the wonder.
Not the fastest computer. Not the biggest. The one that gives an answer worth more than the cost of getting it.
That is the test I keep coming back to. Everything that follows is in service of it. And I have tried to hold to one rule throughout: to be clear at every step about what is established, what is genuinely disputed, and what is still only a bet we should take seriously. The hype in quantum rarely comes from saying false things. It comes from saying hopeful things in the grammar of settled ones. I have done my best not to.
The picture I keep coming back to
When I first tried to learn how a quantum computer is built, I made the mistake everyone makes. I went straight to the qubit. I read about superconducting circuits and trapped ions and topological states of matter, and after a few weeks I knew a lot of physics and almost nothing useful.
The picture that finally helped me is the one below. Six layers. Each one a contract with the layers above and below it. Change one in isolation, and the others still hold. It is the way every working computing system has been built for sixty years, and it turns out to be the way a quantum computer will be built too.

A few things to notice. The application sits at the top - chemistry, materials, optimisation, cryptography. Below it are the high-level languages we write our algorithms in. Then the layer I find most beautiful, the Quantum Intermediate Representation - QIR - sitting in the middle like a hinge. Underneath it are the compilation and resource-estimation tools, then the logical-qubit layer with its error correction, and finally the physical hardware at the bottom.
I have come to think of QIR as the most important piece of software no one outside the field talks about. It is the seam between what humans write and what the hardware runs. It is built on LLVM, the same compiler infrastructure that sits under a great deal of classical computing, which means it inherits decades of compiler engineering for free. It is hardware-neutral, which means the same program can, in principle, target one kind of qubit today and a very different one tomorrow - the work you did above the seam survives the change. It is, in the language of the trade, an abstraction. In the language I prefer, it is a promise.
The reason this matters: if you have to rewrite your program every time the hardware changes, you do not have an industry. You have a series of demos. The history of computing is the history of getting the abstractions right early, so that the work above them does not have to be redone. QIR is the quantum world doing that work.
This is the picture I have inherited. Before I tell you what I think we should build on top of it, I want to stay with the architecture a little longer - because two more pieces of it are worth your trust.
Same shape, one new accelerator
Here is the first thing that made the whole architecture feel less alien to me, and it is almost embarrassing in its simplicity. A quantum computer is not a different universe. It is a new accelerator that slots into the universe we already have.
I am just old enough to remember when a graphics card was something only gamers cared about. Within a decade it was in every laptop; within two it was the most fought-over chip in the world, because it turned out to be what artificial intelligence runs on.
The pattern repeats: exotic, then ordinary, then essential. It happened to the GPU, it is happening to the dedicated AI accelerators now, and the quantum processing unit - the QPU - is simply next in the queue. The cloud data centre does not need to be redesigned. The developer tools do not need to be thrown out. The networks, the security model, the operations - most of it survives.

Look at the mapping above for a minute. Layer by layer, the shape is the same. A high-level language. An intermediate representation. An instruction-set architecture. Microcode. An execution unit. The names on the right are unfamiliar; the structure is not. QIR plays the role that LLVM IR plays in the classical world. The quantum instruction set plays the role of x86. Pulse calibration is the new microcode. The QPU is the new GPU.
I find this comforting and clarifying in equal measure. Comforting because it means the work already poured into cloud-native architecture, developer platforms, DevOps and observability is not wasted. It is the substrate on which the new layer will run. Clarifying because it tells me where to look for the hard problems. They are not in the parts of the stack we already know how to build. They are in the parts that are genuinely new: the orchestration layer itself, the logical qubit, the bandwidth wall between the warm and the cold, and the resource estimator that tells you whether a subroutine is worth attempting in the first place.
The bandwidth wall - the engineering problem most people miss
Here is the thing about quantum computing that took me the longest to grasp. The hardest problem is not the qubit. The qubit is hard. But the qubit is not the wall.
The wall is the bandwidth between the layers. Specifically, between the cold and the warm.
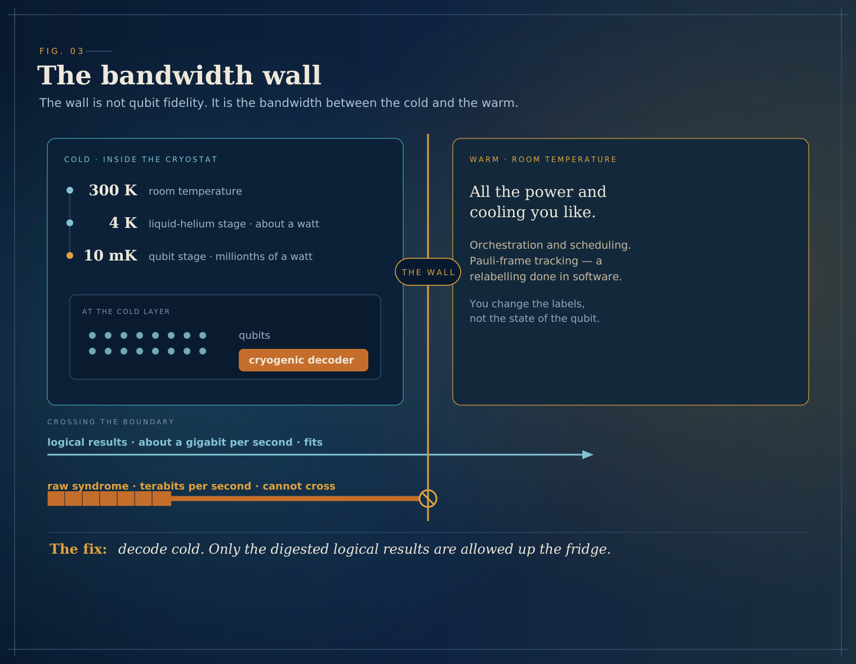
A useful quantum machine keeps its qubits inside a cryostat. Many qubit types live at a few millikelvin - colder than deep space. And the cooling budget down there is brutal: around a watt at the four-kelvin stage, and only millionths of a watt at the millikelvin stage where the qubits actually sit. Either number is a rounding error next to what a room-temperature rack can dissipate. The classical control electronics - the parts that decide which gates to run, that decode error syndromes, that track the Pauli frame - sit at room temperature, where you can have all the power and cooling you like.
The traffic between these two worlds is staggering. At the logical level - instructions going down for logical qubits, results coming back - you need something on the order of a gigabit per second. That is feasible. But underneath, every logical operation expands into thousands of physical operations and measurements, and the raw syndrome traffic at the physical layer runs to terabits per second. There is no universe in which you carry that much data up and out of a cryostat whose coldest stages are cooled by millionths of a watt. The physics simply will not allow it.
The direction the field is converging on is to decode at the physical layer - inside, or very near, the fridge - using cryogenic control electronics that can survive the cold. Only the digested logical results travel back up. The Pauli-frame tracking, which is, beautifully, just a relabeling exercise, happens in software up top, so the qubits never need to be touched to correct certain classes of error. You change the meaning of the labels, not the state of the qubit.
I keep coming back to this part because it is the cleanest example I know of an engineering constraint shaping an architecture. The shape of the machine - what happens cold, what happens warm, what is allowed to cross the boundary - is dictated by physics, not by preference. Whoever solves cryogenic decoding at scale will, I suspect, do more to bring forward useful quantum computing than another decimal place of qubit fidelity. I hold that loosely - it is a bet, not a fact - but it is the bet I would make.
It also tells you something about the layer I will argue for in the next part. Any orchestration layer worth building cannot route arbitrary subroutines to a QPU as if the QPU were just another GPU. The data movement is asymmetric in ways no classical accelerator is. A layer like that will care about how much classical state has to cross the warm–cold boundary, will batch operations to amortise the crossing, and will refuse to route subroutines whose data shape simply does not fit through the bandwidth keyhole. That is not a piece of software anyone has finished writing yet. It is, I think, where some of the most interesting systems work in this field will happen over the next five years.
Coming next
That is the architecture, and that is the wall. None of it is mine. I have learned it from sixty years of computer engineering, and from the physicists and engineers who mapped these constraints long before I came asking questions. In the next part I want to put down something of my own: the layer of software I think belongs on top of all this, and the simple economic rule that should govern it.
Next - Part Two: The Idea I Cannot Stop Thinking About.